This is a contributed post by Moriel Schottlender. Moriel is a physicist turned software engineer turned systems architect, currently working on modernizing Wikipedia’s architecture. She’s an open source enthusiast, right-to-left language support evangelist, and a general domain hoarder. You can find her as @mooeypoo on Twitter, Polywork, and most other social platforms.
A little while ago, after much consideration and thought, I decided to migrate my hackathon-style backend-heavy dynamic tool neutrality.wtf to a serverless architecture, hosted by Netlify. You can read about my thought process about why I ended up not only deciding to migrate but being excited about it in a blog post I wrote about migrating to a serverless approach.
While the last post was talking about the reasons for migration, I thought I’d delve into the practicalities. This is my adventure of how I went about rewriting my (perfectly functional) tool into a more sustainable serverless Jamstack architecture, with a microservice and a shareable npm package.
Refactoring and rewriting code is never an easy thing to do; there are a lot of considerations of where to start, how to approach the new architecture, and what to actually write to make sure the system works and is testable while you rewrite it for production.
If you’ve made the decision to delve into Jamstack and are now facing the daunting challenge of rewriting a monolithic project, I’m hoping this post can guide you through the process in a way that makes it much less daunting, and, dare I hope — even exciting!
Step 1: Planning the architecture
The first step was to try and evaluate what I have, and see what I want to achieve. In the case of neutrality.wtf, the old architecture (written in the caffeine-haze that is a hackathon) was already attempting to achieve some separation of concerns with one repo for the UI and another repo (as a submodule) for the “business logic.” But the two weren’t as separate as they should be, and given 6 years of occasional fixes and features, that separation was rapidly degrading.
This is the benefit of the Jamstack architecture — not only does it lay out the means to make sure your architecture is loosely coupled, but the principles also ensure that the decoupling of the behavior stays separate, manageable, and maintainable as separate pieces. Not only is it a better modern architecture, but it’s also an architecture that empowers you to keep it true and honest even later, when you’re just submitting quick fixes and maintenance work.
So, planning my new architecture, I already knew I wanted to make my code as fortified against “leaking of logic” as possible, and use the loosely-coupled architecture that Jamstack encourages. Luckily, the whole idea of a microservice is that it is designed to be standalone and distinct, not sharing its logic with any external code.
If I could manage to separate the behavior clearly enough, I would guarantee that my architecture would be decoupled enough to make it possible to use different front-ends or different products on top of the service with similar and consistent behaviors. In my case, I could already see how I could make a web entrypoint as well as a mobile one if I wanted to.
Separating standalone behavior: microservice and frontend
Now that I have technical and functional goals, I can start looking at the specifics of the architecture. The two main goals for the migration were to make the architecture decoupled and to make the tool maintainable, with distinct pieces.
But neutrality.wtf has another potential benefit; its core action — taking raw html, replacing words from a dictionary, and returning the html for view — could be useful beyond the specific use case of neutrality.wtf specifically. In other words, instead of making a website with an API, I could generalize the core behavior into a standalone npm library that can be used in other contexts. This would be potentially useful for others, but also make it a lot easier to build step-by-step, with dedicated tests and outputs. Generalization of it can also make it easier to make sure the separation of concerns is kept in the future, even when the tool is no longer under active development, and enable others to contribute.
That sounded like a good plan, so I summed up my target architecture as having three pieces:
- Standalone library: will run the replacement process, the “engine” of the work
- Microservice: will answer the API request, decide what parameters to send to the standalone operation, invoke the library for the core operation, and respond with the result
- Frontend: provide a user interface for the operation and some help pages
This plan also meant that I could, at any point now or in the future, swap around any of those pieces with other pieces, without touching the others. That’s hugely powerful, especially since these types of tools tend to go stale in development — there’s not a whole lot of active development after it becomes stable. So, if I want to update the behavior or add a feature in 2-3 years after not touching the code much, having distinct pieces will make this much more simple and doable.

Step 2: Make things work
I started by setting up the project. The repo for the standalone library came first; it was the easiest to create and start from, and it would be the one that dictates the way the other stacks would behave — a completely separate behavior that should work regardless of the context of the microservice and site. I set it up using the Babel Starter Kit and jumped into writing the initial code and tests. In this stage, I concentrated on the behavior itself; as one of my first mentors used to say: “First make it work, then make it better”. I needed to make sure the basic functionality works at all with the given parameters, before delving into customization and performance.
Then, I set up the repository that would hold the service and front-end at Netlify. Netlify allows for a very quick way to create a microservice — you just create a /.functions folder with your Javascript entrypoint, and that automatically gets shipped and built as the microservice, with a clear entrypoint.
I started with a very barebones implementation, meant to expand the tests of the library to make sure it works with an external call. The original /.functions/replace.js:
const DomWordReplacer = require('@mooeypoo/dom-word-replacer');const dictDefinition = require('../src/data/sampledictionary.json');
async function RunOperation (event) { // Invoke the library const replacer = new DomWordReplacer(dictDefinition); // Replace one way\ let result = replacer.replace(sampleHtml, 'dict1'', 'dict2'); // Replace the other way result = replacer.replace(sampleHtml, 'dict2'', 'dict1');
// Return the results for the UI to present return { statusCode: 200, headers: { "Content-Type": "text/html", }, body: result }}Next, I used Netlify CLI to run my service locally with a netlify dev command, and changed the call of my library to the local instance rather than the published library. This enabled me to change the library code and immediately see the changes reflected in the local environment that Netlify CLI created for me, mimicking the final deployment.
I started building the core functionality of the library and verifying its behavior with a lot of internal tests, occasionally checking my microservice response to make sure it is actually usable through an external invocation. It all worked pretty smoothly; the library did what I needed it to do, and concentrating on test coverage, I made sure it’s as thoroughly tested as possible.
Once the behavior was predictable and working, I added to the microservice a fetch sequence that fetched a specific (medium-sized) article from Wikipedia, fed its HTML to the library, and outputted the result. This was my “real-life test” experiment, and… it failed.
See, my library was delivering what it should have quite well — it expected an html string fetched from a remote website, and then returned the resulting html with my defined dictionary replacement words swapped inside for my to display.
… But the operation took 10 whole seconds to complete. Oops.
I don’t know when was the last time you surfed large pages on the web, but no one waits 10 full seconds for a response. This was completely unacceptable and unusable. I knew the code does what it needs to do. It was now time to make sure it’s working better and more efficiently.
Step 3: Now that it works, make it work better
Now that the code worked I could look at why the operation is taking so long, and how to fix it.
My attempts to keep behavior separate and distinct also meant that I was repeating operations that were expensive. Now that things worked, I needed to reconsider once again what my library will do versus the microservice, and how they can work well together.
Thinking of Performance
neutrality.wtf utilizes the replacement library to grab the raw HTML of a remote website and display it again in the browser inside the neutrality.wtf interface. Because I was taking remote HTML away from their domain context, displaying them in another domain meant all images and assets immediately broke, since the majority of links were relative.
The way to fix that is by adding a base tag in the HTML head. I would need to do that in my use case, but the standalone library could also work in the context of a browser extension, where the page remains in the same domain context, which means this operation isn’t necessary.
A browser extension would also not need to strip <script> tags, while my use case of displaying the website in another domain does require that. So, I had several features I needed to plan for. Where should those live? Should I use the library only for the replacements, making it simple and small, and have my dedicated microservice add and adjust the HTML again for the specific needs of the tool?
That was a strong option, and at first, that’s exactly what I did. The replacement library initially was only used to read the HTML, parse it, replace terms, and output HTML again. My microservice then took the result and parsed it again, adding specifics like the base tag, some CSS styling for the replacements, and stripping tags.
This sounded like a good idea for separation of behavior — except parsing and serializing operations are pretty expensive.
Every time there was a requested remote URL, my microservice parsed and serialized the HTML more than once. Moreover, Neutrality.wtf does a two-way replacement, which means I had to call it to run the replacement for dictionary1 to dictionary2, and then again for dictionary2 to dictionary1, and then have the microservice parse the html again to add the base tag, strip scripts, and add CSS styling. Parsing and serializing each page at least 3 times is a pretty significant performance cost that is unnecessary.
No wonder it was so slow.
Refactoring the library for real uses
Now that I understood that the main culprit of the unacceptable performance was the parsing and serializing, I went back to my standalone library and reconsidered its structure.
I still had use cases where the three operations could be mixed and matched in terms of their usage (some products may not need to perform them all) but there was no doubt that I couldn’t treat them as complete standalone requests; I had to make sure the system only parses the HTML once — then performs whatever operations it needs on the DOM — and serializes it back once.
The answer was to unify the behavior into a single method (replace(...)) that takes in configuration variables. The entire method will run the process that is requested, based on the given config — allowing the code to be adjusted and reused in other places, but not suffer easily fixable performance penalties.
In fact, after this refactoring, the entire two-way replacement operation, including the stripping of scripts, adding <base> tag and CSS styling, took less than 500 milliseconds. Whew!
Happy with this turn of events, I proceeded to add a set of benchmark tests to my library. I downloaded a static version of three of the longest articles on Wikipedia and wrote a test that makes sure the operation takes less than a second to complete.
This turned out to be a good general direction, but before we move on to more of the technical specifics, I wanted to provide one more word of warning about using configuration variables in your library: beware the pitfall of overgeneralization.
Beware the pitfall of overgeneralization
Serverless architecture with microservices is great at encouraging a separation of concerns and building distinct pieces of the system that are scalable and maintainable — but there is a pitfall to watch out for: overgeneralization.
The library has a role to play in the product that I was envisioning, but clearly, it could be used for other use cases as well. I wanted to make it more generic — allowing potential users to utilize the behaviors in products that I don’t necessarily immediately think about. There’s power in that, especially in an open source software — but there’s also a huge risk. Overgeneralizing a piece of software can also make it so complex that it is unusable.
This is a pitfall that is unfortunately pretty common for us engineers. We get excited about a piece of software and add features and flexibility and configuration variables because we can. This is also the source of the known online joke about recognizing tools and websites that were “made by engineers”; it’s not that the software is bad — it’s that these pieces of software tend to be so customizable and flexible, that the user experience ends up being more chaos than order.
There’s a fine line that keeps complexity at bay while allowing for generalized flexible systems to exist and be used. That line is often really hard to keep in control.
Decide where complexity lives
Most technical systems and codebases have complexity in them, and most are trying to abstract that complexity in some way for their users; the question is usually what tradeoffs you’re going to make about the complexity, and where you decide it should “live” in your system.
The more features you add, the more complex the system can end up being for those who use the system. The more you encapsulate the complexity, the cleaner your system becomes, but also all much harder to extend.
Deciding where the line lies depends on the goals you set for yourself, and how you define what users will utilize your system. This is true for both user-facing products and technical codebases like npm libraries, where your users are the developers.
When thinking about my replacement library, I wanted to make it as clean as possible to invoke the replacement operation, which meant I was willing to have the tradeoff of a slightly more complex internal working and internal calculation of the process.
This also helped me keep some features at bay; I tried to keep in mind the main use case of the neutrality.wtf web app, and the secondary use case of a browser extension that replaces words on the page in the tab.
The choices I made for which configuration variable to include were based on those two main features, and those would likely be the considerations I keep making in the future when that library is maintained and extended. If the use cases change in the future, the considerations may change as well, but keeping in mind the main goals and use cases makes sure it’s easier to reign in uncontrolled expansions where the library would be so complex to use, with so many dependent configuration options, that it becomes too complex.
Step 4: The Microservice
Now that the library is carrying the bulk of the work done on the requested page, the remaining question is to see what the microservice does. It was clear that there is a bunch of behavior that depends specifically on the way that neutrality.wtf works that needed to happen before and after sending the information to the library to process. This is where the service comes in. It will act as the validator, mediator, and delivery person connecting the interface and the library “engine” of the tool.
My microservice ended up looking more or less like this:
const { builder } = require("@netlify/functions");const DomWordReplacer = require('@mooeypoo/dom-word-replacer');const dictDefinition = require('../src/data/sampledictionary.json');const fetch = require('node-fetch');
async function RunOperation (event) { // - Read request parameters for the requested type (mobile/desktop) and requested URL // - Validate all user-generated inputs\ // - Fetch the URL // - Validate that there's sensible HTML (not empty contents, no errors, etc)\ // - Invoke the replacer library with the resulting HTML // Convert both ways outright without calling this twice let result = replacer.replace(data.content, 'men', 'women', { baseUrl: urlObj.origin, replaceBothWays: true });
// Output result return { statusCode: 200, headers: { "Content-Type": "text/html", }, body: result }}
exports.handler = builder(RunOperation);You can see the actual code in the repository.
Note that I’ve used Netlify’s builder (On-demand Builders) — this is an extremely useful operation that Netlify provides in order to cache microservice dynamic responses. I wanted to make sure that if the same URL is requested multiple times in a row, the microservice can just serve the result from cache rather than re-run the operation again and again.
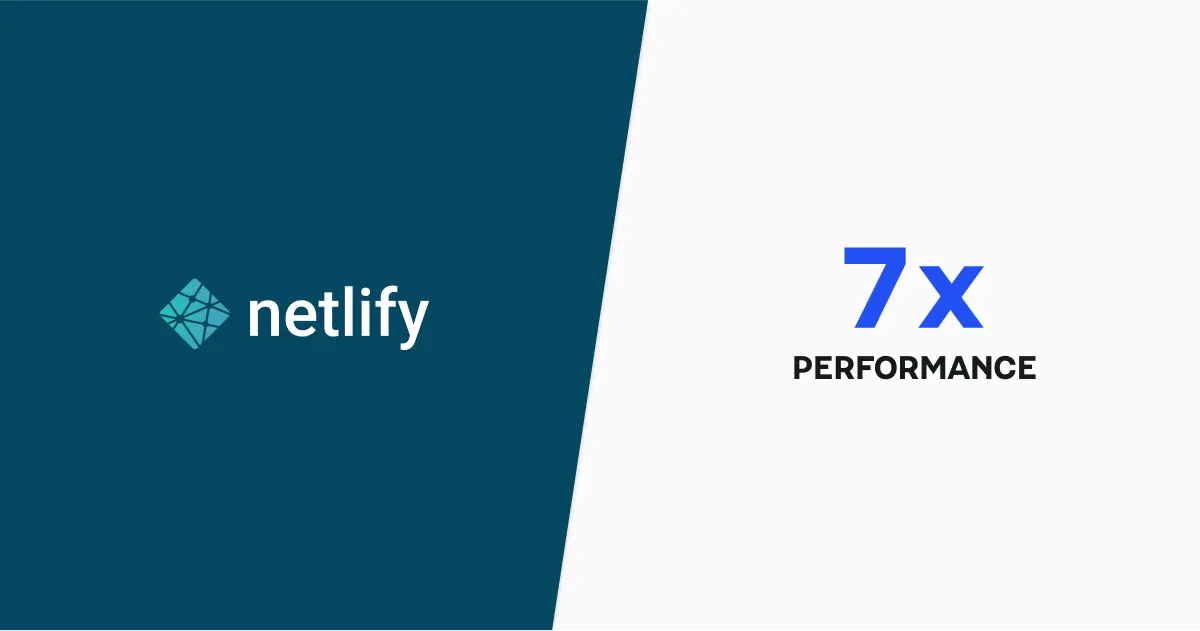
On-demand Builders: A (whopping!) 7x performance improvement
To test the optimization that the On-demand Builders give me, I ran a little test. The on-demand builders cache the microservice result, which means that the initial run will reflect the actual server processing, but subsequent requests to the same URL will be fetched from the cache, bypassing the server workers. I tested this with one of Wikipedia’s longest pages. This page is longer than what I’d usually expect users to submit to the tool, but its size is perfect for benchmarking the performance behavior.
Without the on-demand builders, the system took about 7 seconds to fetch the complete replaced result. Subsequent calls were slightly faster (about 6 seconds), probably because the service was already running. It was still quite a lot, especially for the cases where multiple people share a single URL they’ve replaced — meaning many people open the same requested URL over and over.
With the on-demand builders enabled on the microservice output, cache came into play. While the first run of the requested URL still took about 7 seconds, subsequent runs took an average of 600ms-800ms each. That is over 7 times faster!
On top of that improved speed, using the on-demand builder cache meant that the system skipped activating the actual microservice, this lowered the actual usage of the server resources significantly. Double win — times seven!
The final architecture
Now that I was validated with my usage of caching and separation of concerns and complexity, this is what the final architecture looks like:

Note that each one of those boxes is easily replaceable without touching the others, which is a huge benefit for future features, potentially implementing more platforms to use, and maintenance.
As another layer of abstraction between the UI and microservice, I wanted to make sure that the UI will be independent and oblivious of any technical and architectural decisions I may make in the future about the structure, naming, or behavior of the microservice. For example, future features may warrant a splitting of the microservice or a renaming of the entrypoint; I wanted to make sure that I can do that without making a “breaking change” to anything that requests information from the microservice API — whether it’s the website’s UI or any other tool.
For this, I set up a redirect rule that transformed my “raw” Netlify Function url (that depends on folder and file name) to a nicer standardized API entrypoint URL for the front-end to use. I set this up in the netlify.toml file:
[build] functions = ".functions"
[[redirects]] from = "/api/replace/:type/:url/" to = "/.netlify/functions/api" status = 200 force = trueWhoever or whatever is requesting information from my API will always have to access the /api/replace/ entrypoint, regardless of the code choices I want to make about the microservice itself, or how I’d call or organize its files in the future.
This was super handy, and setting it up in the netlify.toml file is the only thing you need, skipping server or domain configuration in the backend.
Finally, I was ready to add the interface.
Step 5: Create the interface
The entire point of a serverless application is that the architecture is loosely coupled and that the UI is decoupled — the UI is (or multiples of UIs) are independent of the microservice. That means I could make multiple interfaces that talk to my API or replace them seamlessly if I ever need to.
Neutrality.wtf has a single purpose input to accept requested URLs with one or two informational pages, so I chose a very simple vuejs app with vuetify component library. The operation is done by the microservice, so I didn’t even have a need for a full app with state management. It was a simple matter of collecting (and validating) user input, sending it to the microservice, and displaying the result.
Since Netlify treats the function folder as the microservice, I could treat the main folder as the UI, and keep the /.functions folder untouched. I used VueJS CLI to run vue create in my main folder and chose my preferred development utilities and plugins.
While the behavior and architecture of the microservice and UI are separated, the code itself lives in the same repository. This isn’t really mandatory, I could decide that I have different codebases for both of these — making them completely separate, even in the IDE and on GitHub. But there’s one big (enormous!) benefit to deploying them on Netlify as a single site — Netlify’s build tools (Netlify CLI) runs the site as if it’s in production, automatically building the microservice and UI the same way they’d be built on the production server.
This means I have the means to test my microservice and UI on my local environment as if they’re deployed as a full microservice and separate UI, using a single command. I adjusted the package.json scripts to run the vuejs application through Netlify CLI, which would build the microservice for me:
"scripts": { "dev": "netlify dev -c \"npm run serve\"", "serve": "vue-cli-service serve", "build": "vue-cli-service build", },The netlify dev command would build the microservice for me locally, and then (using the -c flag) would immediately run the npm run serve to build and serve the development environment of the front-end.
Since the .functions folder that contains the microservice is in the same folder (and repo) as the front-end, running this compound command gives me another huge benefit: it basically provides me with a fully operational staging server for both front- and back-end changes.
Netlify’s deployment CI/CD includes a PR preview; when I deploy I don’t need to use the netlify dev command, since the system automatically builds the microservice for me. I just tell Netlify to run its internal operations and then npm run build to run the vuejs front-end, and whatever changes I make to either the UI or microservice, Netlify will automatically produce a working version of the entire system for me — locally and in PR previews — making it possible for me to test and QA the entire system together before I deploy it.
Staging servers cost a lot of money and take a lot of effort to keep up with the deployment server. Now, I get it done for me!
Step 6: Rejoice!
This whole adventure meant not just refactoring code, but wholly rewriting it. And yet, it also served to produce a final product that has a maintainable architecture, potential for adding features with the least amount of hassle, and tools and utilities that were really beyond what I’d have gotten for the previous traditional server deployment.
To summarize, here are the biggest advantages of the architecture migration:
- A consistent development environment: Netlify CLI means I can run the entire site — front- and back-end — in the local environment, with little hassle. Not only that, but any new collaborator can do the same by cloning the repo, installing dependencies, and running
npm run dev, no matter what operating system or tooling they use. - A staging server: Netlify’s PR previews mean I essentially have a full-fledged staging server, working with both microservice and front-end, for any potential fix to the site. This wasn’t something I had time to set up when I was working on my own server tooling.
- A standalone npm library: I can now use the core behavior in many other contexts, and provide that behavior to others. Win!
- Decoupled architecture: My microservice is completely decoupled from the UI, which means I can maintain each of those separately, and update or upgrade either of those separately.
- … With unified CI/CD: While the architecture is decoupled and allows me to swap the pieces individually, there’s also a huge benefit for Netlify’s ability to utilize the same repository, which means that my builds are always true-to-reality, as they’re always dependent on the exactly correct state of the UI and microservice whether my code changes involved either or both.
- Caching: Netlify’s CDN gives me caching for the front-end, and Netlify’s On-demand builders give me caching for the microservice output, and I didn’t need to set anything up or configure any special tooling.
So there you have it. My adventures in modernizing neutrality.wtf, a dynamic tool that depends on user input, made during a hackathon.
I can already see that tweaks and bug fixes are significantly easier to deal with and fix and that my separation of concerns and focus on deciding where my complexity lives make followup code decisions a lot easier and much more sustainable.
Where have you been all my life, Jamstack?
If you’re still on the fence about whether to migrate your tool to serverless, I hope this gave you the needed nudge to move ahead with it, and demystified some of the processes that are done to do it right.







